Pipelining TensorCore and SparseCore operations#
This page explains an optimization technique to overlap SparseCore (SC) embedding computations with the TensorCore (TC) computations to improve training throughput.
The API provides a step() function that takes the SparseCore forward pass,
TensorCore forward/backward pass, and SparseCore backward pass functions as
input. The step() function manages the pipeline state and executes the
functions in the correct order.
The embedding_pipelining_utils module provides utilities for managing
this overlap.
For an example of usage see: jax_sc_shakespeare_pipelined_jit_test.py
Converting to Pipelined Training#
Turning a regular, non-pipelined training loop into a pipelined one requires moving from a single step function to a pipelined step function that manages state across iterations.
Non-pipelined Training Loop:
The following is an example that demonstrates converting a regular training loop
to a pipelined one using the embedding_pipelining_utils module.
for step in range(num_steps):
batch = prepare_batch(step)
# 1. SparseCore Forward
sc_activations, _ = sc_fwd_fn(batch.sparse, variables)
# 2. TensorCore Forward/Backward
sc_grads, output, state, _ = tc_fn(sc_activations, batch.dense, state)
# 3. SparseCore Backward (Update)
variables, _ = sc_bwd_fn(batch.sparse, sc_grads, variables)
# Process output...
Pipelined Training Loop:
def prepare_input(step_counter):
if step_counter < num_steps:
return ep_utils.CurrentStepInput(
sparse_inputs=fetch_sparse(step_counter),
dense_inputs=fetch_dense(step_counter),
)
else:
# Provide dummy inputs for pipeline draining steps
return jax.tree.map(jnp.zeros_like, first_batch_input)
pipeline_state = ep_utils.get_initial_state(...)
# Pipelining requires 2 extra steps (filling and draining)
for step_counter in range(num_steps + 2):
# Prepare input for the current iteration
pipeline_input = prepare_input(step_counter)
fake_tc_step = not ep_utils.is_output_valid(step_counter, num_steps)
# Single call to ep_utils.step handles all stages
output, _, state, variables, pipeline_state = ep_utils.step(
pipeline_input, state, variables, pipeline_state,
sc_fwd_fn, tc_fn, sc_bwd_fn, fake_tc_step=fake_tc_step)
if ep_utils.is_output_valid(step_counter, num_steps):
# Process output from step_counter - 1
process_metrics(output)
Special handling for boundary steps#
The overlapping execution of SparseCore and TensorCore computations from different batches requires special handling for the first and last steps of the training loop.
Skipping TensorCore execution during pipeline filling and draining#
The tc_function (which runs the main model’s forward and backward pass)
should only run when it has valid inputs from the previous step’s SC forward
pass, and when its gradients are needed for a future SC backward pass. In the
very first and very last pipeline steps, one of these conditions isn’t met.
The flag fake_tc_step=True is used to skip the actual TC computation in
these steps.
The utility function is_output_valid() returns True only for
steps 1 to num_steps, signaling that TC should only run in those steps.
# Pipeline step 0: filling (SC fwd only)
# Pipeline steps 1 to num_steps: steady state
# Pipeline step num_steps + 1: draining (SC bwd only)
fake_tc_step = not ep_utils.is_output_valid(step_counter, num_steps)
Providing dummy inputs during pipeline draining#
We only have num_steps batches of real input data (0 to num_steps-1).
However, the pipeline requires num_steps + 2 iterations to complete. In the
last two steps (num_steps and num_steps+1), we need to provide dummy
inputs to satisfy the function signatures.
if step_counter < num_steps:
pipeline_input = prepare_real_batch(step_counter)
else:
# Use zeros_like to provide dummy inputs for extra steps
pipeline_input = jax.tree.map(jnp.zeros_like, dummy_input_template)
Passing data between stages using auxiliary output (Aux)#
The SparseCore (SC) and TensorCore (TC) functions can return auxiliary data
(aux) that is passed to subsequent stages in the pipeline. This is useful
for passing state or intermediate results that are not part of the primary
training data (like activations or gradients).
sc_fwd_aux: Returned by the SC forward function. It is passed as an argument to the TC function in the next pipeline step.tc_aux: Returned by the TC function. It is passed as an argument to the SC backward function in the next pipeline step.sc_bwd_aux: Returned by the SC backward function. It is returned as part of thestep()function’s output and can be used for logging or monitoring.
The types of these auxiliary data are defined by the user when instantiating the
stage functions (ScFwdStageFun, TcStageFun,
ScBwdStageFun). By default, if no auxiliary data is needed, None
should be returned.
Example: Passing metadata from SC Forward to TC
def sc_fwd_fn(sparse_inputs, variables):
# Perform lookup...
activations = ...
# Pass metadata (e.g., sequence lengths) to TC
sc_fwd_aux = {"seq_lengths": sparse_inputs.lengths}
return activations, sc_fwd_aux
def tc_fn(activations, dense_inputs, state, sc_fwd_aux):
# Use metadata from SC Forward
seq_lengths = sc_fwd_aux["seq_lengths"]
# ... perform TC computations ...
return gradients, output, state, tc_aux
Internal Implementation Details#
This section describes how the pipeline stages overlap and the cycles required to process multiple batches.
Pipelining works by passing n batches (0 based indexing).
Note
Output from SC bwd (i-2) is used in SC fwd (i)
i.e. [SC BWD (i-2) -> SC FWD i] (SC) and [TC FWD BWD (i-1)] (TC) are
run in parallel
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
E: Extra Steps
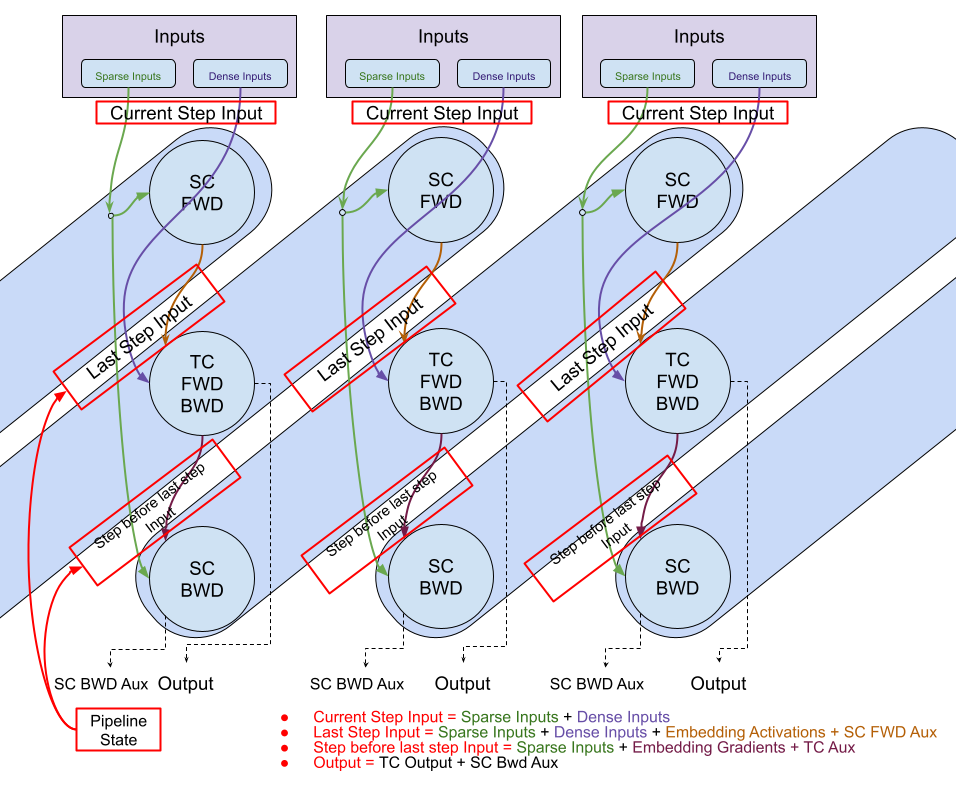
API#
- step(pipeline_input, tc_train_state, embedding_variables, pipeline_state, sc_fwd_function, tc_function, sc_bwd_function, *, fake_tc_step)#
Step the pipeline.
- Parameters:
pipeline_input (CurrentStepInput[_SparseInput, _DenseInput]) – Inputs for the current step (sc_fwd, tc, sc_bwd).
tc_train_state (_TcTrainState) – Training state for the TensorCore.
embedding_variables (_EmbeddingVariables) – Embedding variables for the SparseCore.
pipeline_state (PipelineState[_SparseInput, _DenseInput, _EmbeddingActivations, _EmbeddingGradients, _TcAux, _ScFwdAux, _PipelineOutput]) – Internal pipeline state that contains the inputs and outputs for and from the three stages that is sequentially shifted by one step at each pipeline execution.
sc_fwd_function (ScFwdStageFun[_SparseInput, _EmbeddingActivations, _EmbeddingVariables, _ScFwdAux]) – SparseCore forward pass function.
tc_function (TcStageFun[_EmbeddingActivations, _DenseInput, _EmbeddingGradients, _PipelineOutput, _TcTrainState, _ScFwdAux, _TcAux]) – TensorCore forward/backward pass function.
sc_bwd_function (ScBwdStageFun[_SparseInput, _EmbeddingGradients, _EmbeddingVariables, _TcAux, _ScBwdAux]) – SparseCore backward pass function.
fake_tc_step (bool) – If true, fake the TC step by copying the embedding gradients to the pipeline output.
- Returns:
A tuple of (pipeline_output, auxiliary output from SC BWD, updated train_state, updated embedding_variables, updated pipeline_state).
- Return type:
tuple[_PipelineOutput, _ScBwdAux, _TcTrainState, _EmbeddingVariables, PipelineState[_SparseInput, _DenseInput, _EmbeddingActivations, _EmbeddingGradients, _TcAux, _ScFwdAux, _PipelineOutput]]
- get_initial_state(pipeline_input, tc_train_state, embedding_variables, sc_fwd_function, tc_function, dense_input_sharding=None, sparse_input_sharding=None)#
Get the initial pipeline state.
- Parameters:
pipeline_input (CurrentStepInput[_SparseInput, _DenseInput]) – Input to the sc_fwd, tc and sc_bwd for the current step.
tc_train_state (_TcTrainState) – Training state for the TensorCore.
embedding_variables (_EmbeddingVariables) – Embedding variables for the SparseCore.
sc_fwd_function (ScFwdStageFun[_SparseInput, _EmbeddingActivations, _EmbeddingVariables, _ScFwdAux]) – SparseCore forward pass function.
tc_function (TcStageFun[_EmbeddingActivations, _DenseInput, _EmbeddingGradients, _PipelineOutput, _TcTrainState, _ScFwdAux, _TcAux]) – TensorCore forward/backward pass function.
dense_input_sharding (Sharding | None) – The sharding of the dense inputs.
sparse_input_sharding (Sharding | None) – The sharding of the sparse inputs.
- Returns:
Initial pipeline state.
- Return type:
PipelineState[_SparseInput, _DenseInput, _EmbeddingActivations, _EmbeddingGradients, _TcAux, _ScFwdAux, _PipelineOutput]
- get_pipeline_state_sharding(pipeline_state_cls, dense_input_sharding, sparse_input_sharding, pipeline_output_sharding, tc_aux_sharding)#
Get the sharding for the pipeline state.
- Parameters:
pipeline_state_cls (Callable[[...], _PipelineStateT]) – The class of the pipeline state instantiated with user type parameters.
dense_input_sharding (_ShardingT) – The sharding of the dense inputs.
sparse_input_sharding (Sharding) – The sharding of the sparse inputs.
pipeline_output_sharding (_ShardingT) – The sharding of the output from the TensorCore.
tc_aux_sharding (_ShardingT) – The sharding of the auxiliary data from the TensorCore.
- Returns:
The sharding of the pipeline state.
- Return type:
_PipelineStateT
- get_pipeline_train_steps(num_steps)#
Get the number of pipeline train steps.
- Parameters:
num_steps (int)
- Return type:
int
- is_output_valid(pipeline_step, num_steps)#
Check if the output of the pipeline is valid.
Output is only valid when the TensorCore (TC) runs which is from step 1 to num_steps.
- Parameters:
pipeline_step (int) – Current pipeline step (0 based indexing).
num_steps (int) – Total number of steps.
- Returns:
True if the output is valid, False otherwise.
- Return type:
bool
- get_default_sc_fwd_function(feature_specs, global_mesh)#
Get the default SC fwd function.
- Parameters:
feature_specs (FeatureSpec | Sequence[FeatureSpec] | Mapping[str, FeatureSpec]) – Feature specs for the embedding layer.
global_mesh (Mesh) – Global mesh for the embedding layer.
- Returns:
A function that takes default pipeline stage input/output and embedding variables as input and returns updated default pipeline stage input/output.
- Return type:
ScFwdStageFun[PreprocessedInput, Array | None, EmbeddingVariables | Sequence[EmbeddingVariables] | Mapping[str, EmbeddingVariables], None]
- get_default_sc_bwd_function(feature_specs, global_mesh)#
Get the default SC bwd function.
- Parameters:
feature_specs (FeatureSpec | Sequence[FeatureSpec] | Mapping[str, FeatureSpec]) – Feature specs for the embedding layer.
global_mesh (Mesh) – Global mesh for the embedding layer.
- Returns:
A function that takes default pipeline stage input/output and embedding variables as input and returns updated embedding variables.
- Return type:
ScBwdStageFun[PreprocessedInput, Array | None, EmbeddingVariables | Sequence[EmbeddingVariables] | Mapping[str, EmbeddingVariables], None, None]
- class PipelineState(pipeline_step, last_step_inputs, step_before_last_step_inputs, placeholder_output, placeholder_tc_aux)#
Pipeline state.
- Parameters:
pipeline_step (Array)
last_step_inputs (LastStepInput[_SparseInput, _DenseInput, _EmbeddingActivations, _ScFwdAux])
step_before_last_step_inputs (StepBeforeLastStepInput[_SparseInput, _EmbeddingGradients, _TcAux])
placeholder_output (_PipelineOutput)
placeholder_tc_aux (_TcAux)
- pipeline_step#
Current pipeline step (0 based indexing). This is the step number of the pipeline, not the training step.
- Type:
- placeholder_output#
Placeholder output from the current pipeline step (TC) when run_tc=False and jax.lax.cond needs a placeholder value.
- Type:
jax_tpu_embedding.sparsecore.lib.nn.embedding_pipelining_utils._PipelineOutput
- placeholder_tc_aux#
Placeholder auxiliary data from the current pipeline step (TC) when run_tc=False and jax.lax.cond needs a placeholder value.
- Type:
jax_tpu_embedding.sparsecore.lib.nn.embedding_pipelining_utils._TcAux
- replace(**updates)#
Returns a new object replacing the specified fields with new values.
- class CurrentStepInput(sparse_inputs, dense_inputs)#
Step i inputs.
- Parameters:
sparse_inputs (_SparseInput)
dense_inputs (_DenseInput)
- replace(**updates)#
Returns a new object replacing the specified fields with new values.
- class LastStepInput(sparse_inputs, embedding_activations, dense_inputs, sc_fwd_aux)#
Step i-1 inputs.
- Parameters:
sparse_inputs (_SparseInput)
embedding_activations (_EmbeddingActivations)
dense_inputs (_DenseInput)
sc_fwd_aux (_ScFwdAux)
- replace(**updates)#
Returns a new object replacing the specified fields with new values.
- class StepBeforeLastStepInput(sparse_inputs, embedding_gradients, tc_aux)#
Step i-2 inputs.
- Parameters:
sparse_inputs (_SparseInput)
embedding_gradients (_EmbeddingGradients)
tc_aux (_TcAux)
- replace(**updates)#
Returns a new object replacing the specified fields with new values.
- class ScFwdStageFun(*args, **kwargs)#
Protocol for the SparseCore forward pass function.
- __call__(sparse_inputs, embedding_variables)#
SparseCore forward pass function.
- Parameters:
sparse_inputs (_SparseInput) – Sparse inputs for the SparseCore forward pass.
embedding_variables (_EmbeddingVariables) – Embedding variables for the SparseCore.
- Returns:
A tuple of embedding activations and auxiliary data to TC.
- Return type:
tuple[_EmbeddingActivations, _ScFwdAux]
- class TcStageFun(*args, **kwargs)#
Protocol for the TensorCore forward/backward pass function.
- __call__(embedding_activations, dense_inputs, train_state, sc_fwd_aux=None)#
TensorCore forward/backward pass function.
- Parameters:
embedding_activations (_EmbeddingActivations) – Embedding activations from the SparseCore.
dense_inputs (_DenseInput) – Dense inputs for the TensorCore.
train_state (_TcTrainState) – Train state for the TensorCore.
sc_fwd_aux (_ScFwdAux | None) – Auxiliary data from the SparseCore forward pass.
- Returns:
A tuple of embedding gradients, pipeline output, updated train state, and auxiliary data to SC BWD.
- Return type:
tuple[_EmbeddingGradients, _PipelineOutput, _TcTrainState, _TcAux]
- class ScBwdStageFun(*args, **kwargs)#
Protocol for the SparseCore backward pass function.
- __call__(sparse_inputs, embedding_gradients, embedding_variables, tc_aux=None)#
SparseCore backward pass function.
- Parameters:
sparse_inputs (_SparseInput) – Sparse inputs for the SparseCore backward pass.
embedding_gradients (_EmbeddingGradients) – Embedding gradients from the TensorCore.
embedding_variables (_EmbeddingVariables) – Embedding variables for the SparseCore.
tc_aux (_TcAux | None) – Auxiliary data from the TensorCore forward/backward pass.
- Returns:
A tuple of updated embedding variables and auxiliary output.
- Return type:
tuple[_EmbeddingVariables, _ScBwdAux]